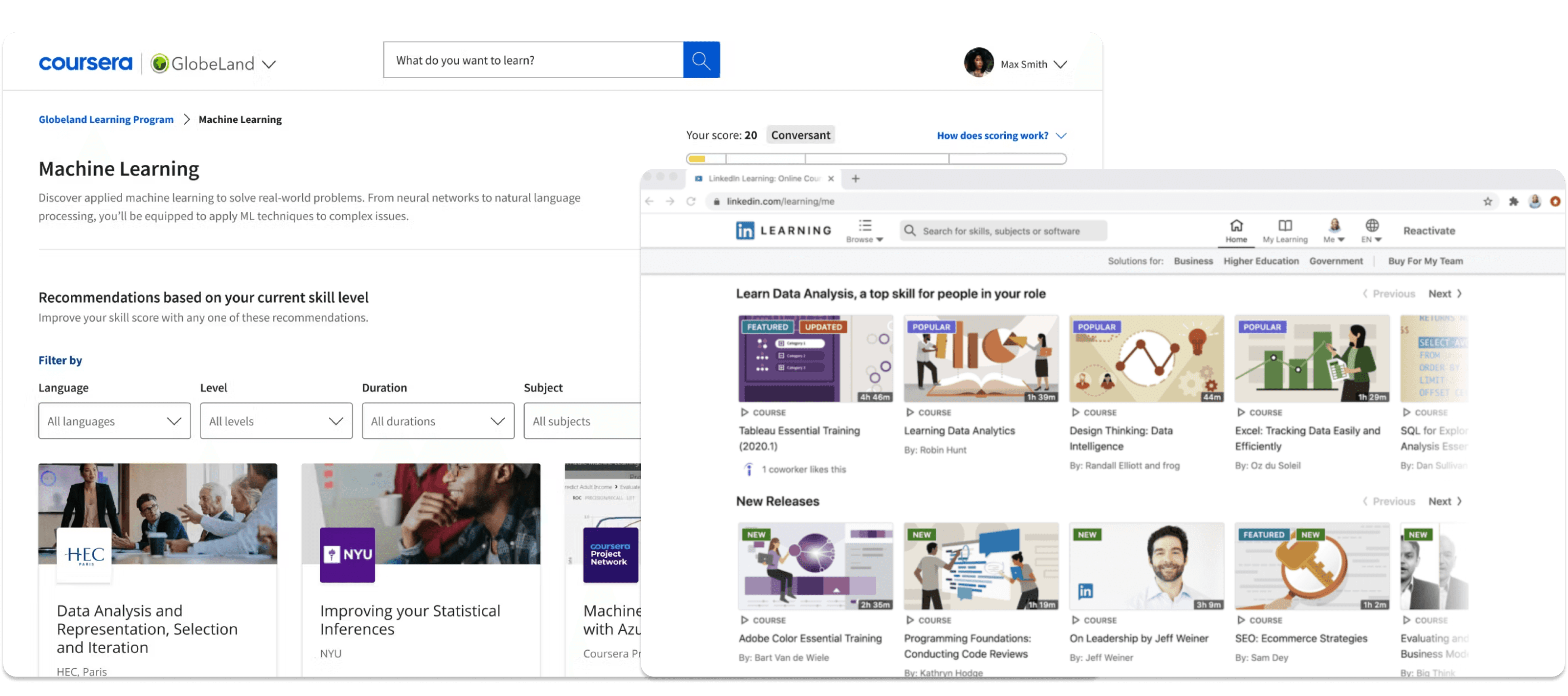
After deploying the initial version, I tested with Duke students and iterated based on their feedback.
Keyword expansion wasn't broad enough. Students searching for "human behavior" expected psychology, sociology, anthropology, and behavioral economics, but early results were too narrow. I enhanced the LLM prompt engineering to expand intent more aggressively across related disciplines.
Results felt generic. The "Why this course?" explanations initially read like they could apply to any student. I refined the prompt to generate reasoning that directly references the user's specific query language, making each explanation feel personally relevant.
Workload signals needed recalibration. I switched TF-IDF from default weighting to binary weighting, focusing on vocabulary diversity rather than frequency. This slightly reduced Random Forest accuracy (87.2% to 86.0%) but improved real-world recommendation relevance. A tradeoff I chose deliberately.
The UI needed polish. Based on feedback about readability during quick scanning, I improved visual hierarchy with better typography, line heights, and gradient backgrounds to help result cards stand out.